

Data+AI Summit 2025 Edition part 1
Your long awaited Data+AI recap

Missed the DATA+AI Summit? Don’t worry, we've got you covered! Here is what you do not want to miss to stay up to date with the latest Data + AI Summit !
Open Source + Community
Databricks Free Edition is available for all!
Want to try Databricks ? With Databricks Free Edition, you can learn and explore the latest data and AI technologies for FREE.
Want to get started? Sign up for Free Edition today and read the supporting documentation to begin - you’ll get a workspace out of the box, ready to use! Learn more from Tarek Madkour, Director of Product Management at Databricks
Doubling down on Open Source with Declarative Pipelines!
Previously known as DLT, Databricks shared with the Apache Spark™ ecosystem Declarative Pipelines! It adds Declarative capabilities to Spark: tell the engine your transformation in SQL or Python, and it’ll do the hard work for you.
This will land in the next Apache Spark. In the meantime, you can review the Jira and community discussion for the proposal, or hear all the details from Michael Armburst!
Unity Catalog
No more format lock-in, silos, or fragmented governance. Unity Catalog is now the only unified catalog that seamlessly connects all your data—Delta Lake or Apache Iceberg™—across any engine or cloud.
Break Format Barriers:
Unity Catalog fully supports the Iceberg REST Catalog API for reading and writing.Store your data in open Iceberg tables managed by Unity Catalog, and read/write from DBSQL, Spark, Trino, Snowflake, Amazon EMR and more.
Iceberg catalog federation lets you govern and query Iceberg tables in AWS Glue, Hive Metastore, and Snowflake Horizon without copying or extra pipelines. This allows you to bring full Databricks governance and security to external catalogs, breaking down legacy data boundaries.Share Data Without Limits:
Delta Sharing for Iceberg enables you to share Unity Catalog and Delta tables with any client via the Iceberg REST Catalog API. Collaborate without friction,One Semantic Layer for All
Unity Catalog now provides a unified business-aware experience for every data stakeholder:
Unity Catalog Metrics
Make business metrics a first-class citizen. Define KPIs once at the lakehouse layer. Use them everywhere in dashboards, notebooks, Genie, Lakeflow jobs, and soon in top BI and observability tools.Curated Discovery and Intelligent Insights
The new business domain marketplace and discover experience turns Unity Catalog into an internal data hub:Certified data products, metrics, dashboards, AI agents, and Genie spaces—all organized by business unit (Sales, Marketing, Finance, etc.).
AI-powered recommendations, intelligent signals (quality, usage, relationships), and curation surface the highest-value assets, so users always find what’s trustworthy and relevant.
Certifications and deprecation tags signal data trust, lifecycle, and business relevance directly in your workflow.
Attribute-Based Access Control (ABAC)
Define dynamic tag-driven access policies at any level catalog, schema, or table. ABAC policies now inherit across the hierarchy and can leverage tags for region, business domain, sensitivity, and beyond. Combined with new data classification, sensitive and regulated data is automatically detected and protected, simplifying policy management and audits at any scale.Tag Policies
Account-level policies ensure that tags used for classification, cost attribution, and compliance remain consistent.Request for Access
Users can now instantly request access to any asset, streamlining delivery and reducing friction between data consumers and governance teams.
DBSQL
With the launch of Predictive Query Execution and Photon Vectorized Shuffle, queries can be up to 25% faster, on top of the 5x gains we saw over the last years. These new engine improvements roll out automatically across all DBSQL Serverless warehouses at zero additional cost.

A bunch of functions and features has been added lately. This list is not exhaustive - SQL team is shipping very fast to provide state of the art Datawarehousing capabilities
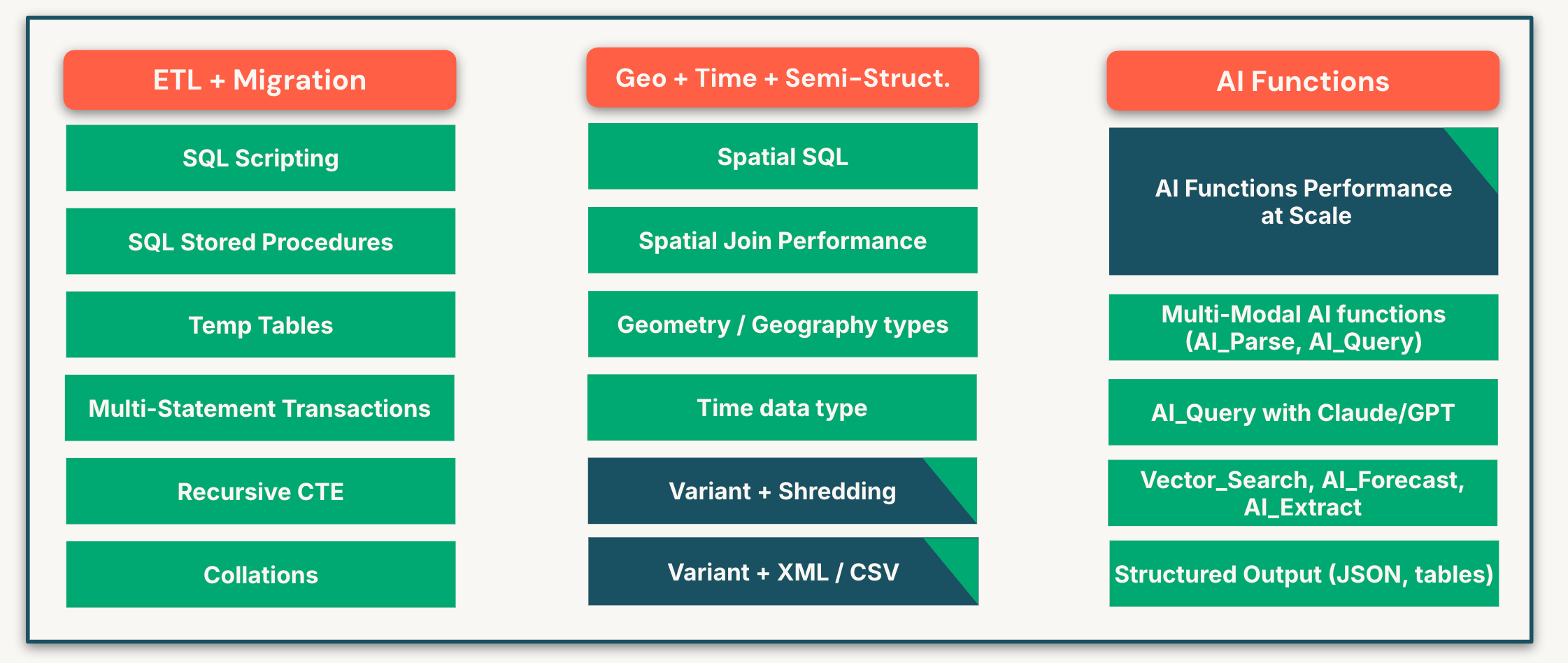
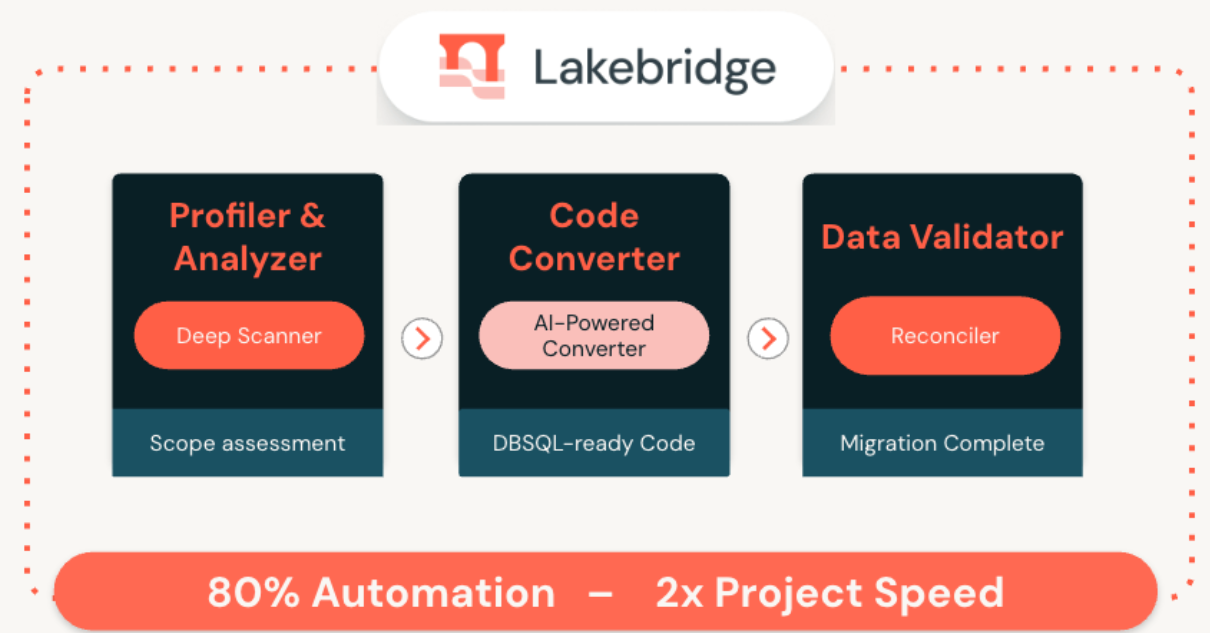
Lakebridge: Free, Open Data Migration to DBSQL using AI powered tooling
Migrating from legacy, siloed data warehouses is key to unlocking faster insights, reducing costs, and unifying analytics & AI on Databricks. But complex code and hidden dependencies make it risky.
Lakebridge is a free tool that automates up to 80% of the migration, making the process faster and safer.
It includes three core components:
Analyzer – Assesses your legacy environment in detail.
Converter – Translates legacy SQL and ETL (including stored procedures) into Databricks SQL or Spark SQL.
Validator – Verifies data accuracy with built-in reconciliation tools.
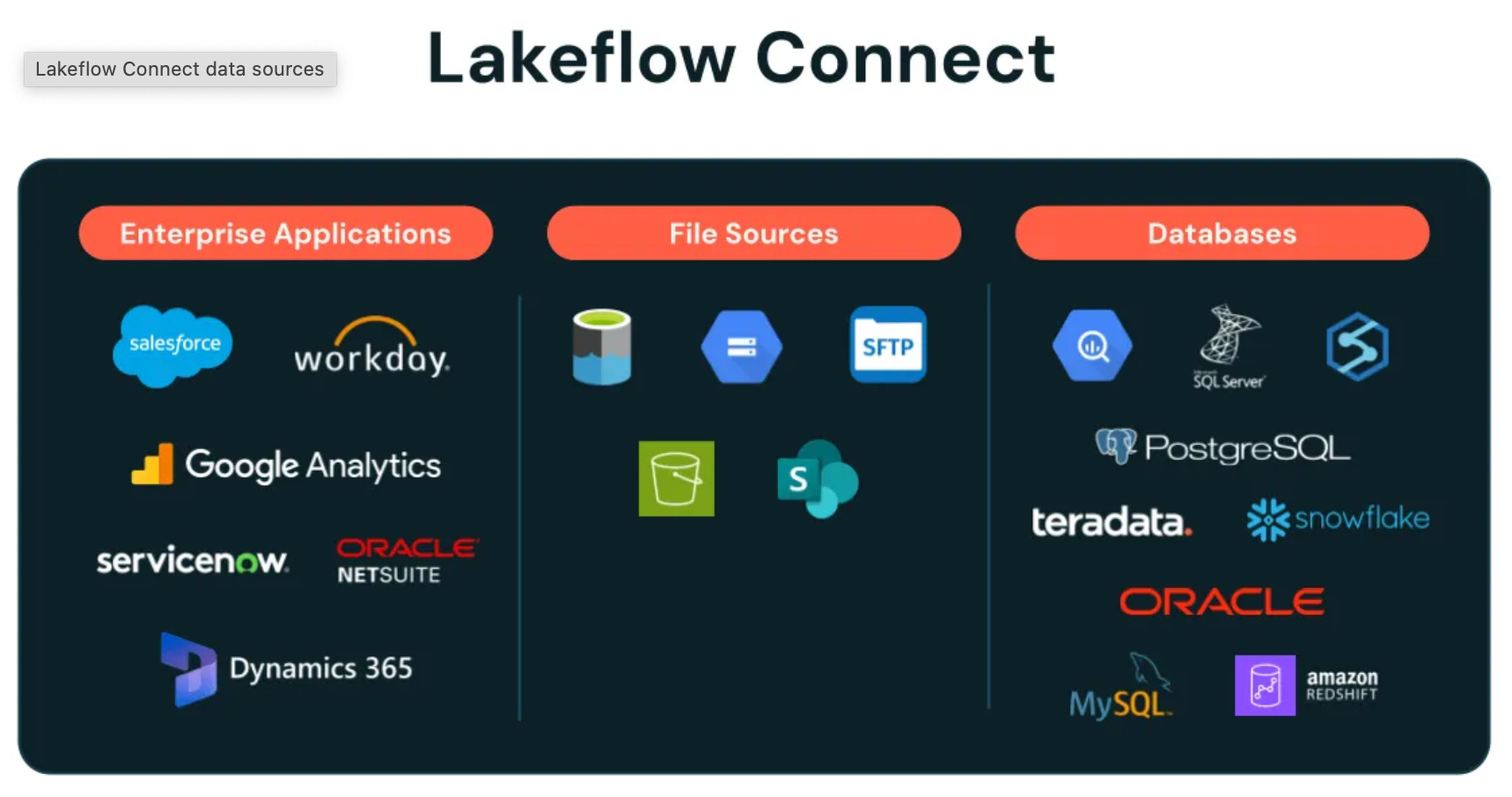
Data ingestion with Lakeflow
Databricks Lakeflow is now GA. It does include three core components:
Lakeflow Connect
Ingest from enterprise apps, databases, file systems and real-time streams with just a few clicks
Zerobus was announced. It is an innovative approach for pushing event data directly to your lakehouse, bringing you closer to the data source and eliminating data hops and operational burden to provide high-throughput direct writes with low latency. Zerobus is part of Lakeflow Connect.

Lakeflow Declarative Pipelines (previously DLT)
Scalable ETL pipelines built on the open standard of Spark Declarative Pipelines, integrated with governance and observability, and providing a streamlined development experience through a modern IDE for data engineering
Lakeflow Jobs
Native orchestration for the Data Intelligence Platform supporting advanced control flow, data triggers, and comprehensive monitoring.
Lakeflow Designer: probably the most exciting addition!
Databricks announced an AI-Powered No Code ETL called Lakeflow Designer that is fully integrated with the Databricks Data Intelligence Platform. With a visual canvas and built-in natural language interface, Designer lets business analysts build scalable production pipelines and perform data analysis without writing a single line of code–all in a single. Every pipeline built in Designer creates a Lakeflow Declarative Pipeline under the hood.
Lakebase
Lakebase is Databricks new, fully managed Postgres-compatible OLTP database, purpose-built to power modern operational and AI-driven applications within the Databricks Lakehouse Platform.
Separation of Compute and Storage: Store data in open formats on low-cost object storage, scaling compute and storage independently.
Serverless and Autoscaling: Instantly scale compute resources to meet workload demands—or scale to zero when idle, so you only pay for storage when not in use.
Database Branching: Instantly create isolated database branches for testing, feature development, or experiment rollback using copy-on-write, just as you would in a Git repo—ideal for development, auditing, and managing AI agents.
Unity Catalog Integration: Register Lakebase as a catalog, enabling seamless management, governance, and access controls unified with your Lakehouse data.
Managed Data Synchronization: Sync operational data between Lakebase and Delta tables, reducing custom ETL and keeping data consistent for analytics and operational use cases.
Performance & Availability: Multi-zone replication, point-in-time recovery, and enterprise-grade security with automated backups. Monitor performance metrics in real time.
AI-Ready: Designed for high-concurrency, low-latency workloads required for modern AI applications and agents—enables native development of GenAI and real-time analytics apps.
Why Lakebase?
Lakebase accelerates the development of intelligent operational applications by bringing transactional and analytical capabilities together. Its instant scalability, powerful branching, and serverless operation help teams deliver faster, run more efficient workloads, and reduce operational overhead and cost. This marks a significant step toward simplifying enterprise data architectures—replacing costly, legacy OLTP stacks with a single, cloud-native platform for all data-driven applications.
It’s a game-changer for all your Databricks applications!!
Stay tuned for the Part 2 - coming in a few days!