

What's new in Databricks - November 2024

Novembre 2024 Release Highlights
Predictive Optimization is now enabled for all the new Databricks accounts
Fine grained access control on Single user compute is now GA
Unity Catalog
Service Credentials
Service credentials enable a secure authentication with your cloud tenant’s services using IAM roles and UC. It lets you govern access from Databricks to external cloud services like Glue or AWS Secret Manager. Learn more
Predictive Optimization is now enabled for all the new Databricks accounts
Previously you had to enable it through the admin account. Predictive Optimization can run Optimize, Vacuum and Analyze automatically
New table available in System tables
System.compute.warehouse table record SQL warehouse configuration

Cross View Sharing
Databricks recipients can now query shared views using any Databricks compute resource. Previously, if a recipient’s Databricks account was different from the provider’s account, recipients could only query a shared view using a serverless SQL warehouse
Data Engineering
Fine grained access control on Single user compute is now GA
In Databricks Runtime 16.0 and above, fine-grained access control on single user compute is generally available. In workspaces enabled for serverless compute, if a query is run on supported compute such as single user compute and the query accesses any of the following objects, the compute resource passes the query to the serverless compute to run data filtering:
Views defined over tables on which the user does not have the
SELECTprivilege.Dynamic views.
Tables with row filters or column masks applied.
Materialized views and Streaming tables.
Create liquid clustered tables during streaming writes
You can now use ClusterBy to enable liquid clustering when creating new tables with Structured Streaming writes. Learn more
Optimize Full
You can optimize all records in a table that uses liquid clustering including data that has been previously clustered. Learn more
Avro updates
You can now use the recursiveFieldMaxDepth option with the from_avro and the avro data source. This option sets the maximum depth for schema recursion on the avro data source. Learn more
Databricks now supports Avro Schema reference with Confluent Schema registery. Learn more
Query history and query profile support for Delta Live tables
You have now improved tools for monitoring query performance in DLT. You can use the Compute filter on the query history page to show only queries processed using Delta Live Tables compute.
Platform
Enhanced experience in the notebooks
When you hover over the name of a Unity Catalog table in a notebook cell, the tooltip now includes the owner, last updated, size, description and a link to view the table in the catalog explorer
Expanded support for Python debugger in notebooks
The built in Python debugger in Databricks notebooks now is supported on Serverless compute.
Improved web terminal experience
Support for configuration files: You can now set persistent configurations for your Databricks web terminal with .bashrc configuration files.
Command cycle history: You can now cycle through commands executed in previous sessions with the “Up” and “Down” arrow keys. This makes it easy to recall and reuse previous commands without retyping them.
Shared Cluster Support: Our improved web terminal is available on shared clusters in Databricks Runtime 15.1 and above.
AI/BI Dashboards
Dashboard and Genie integration
Start a chat with Genie from published dashboards in the same interface, which automatically creates a AI/BI Genie space based on data in dashboards
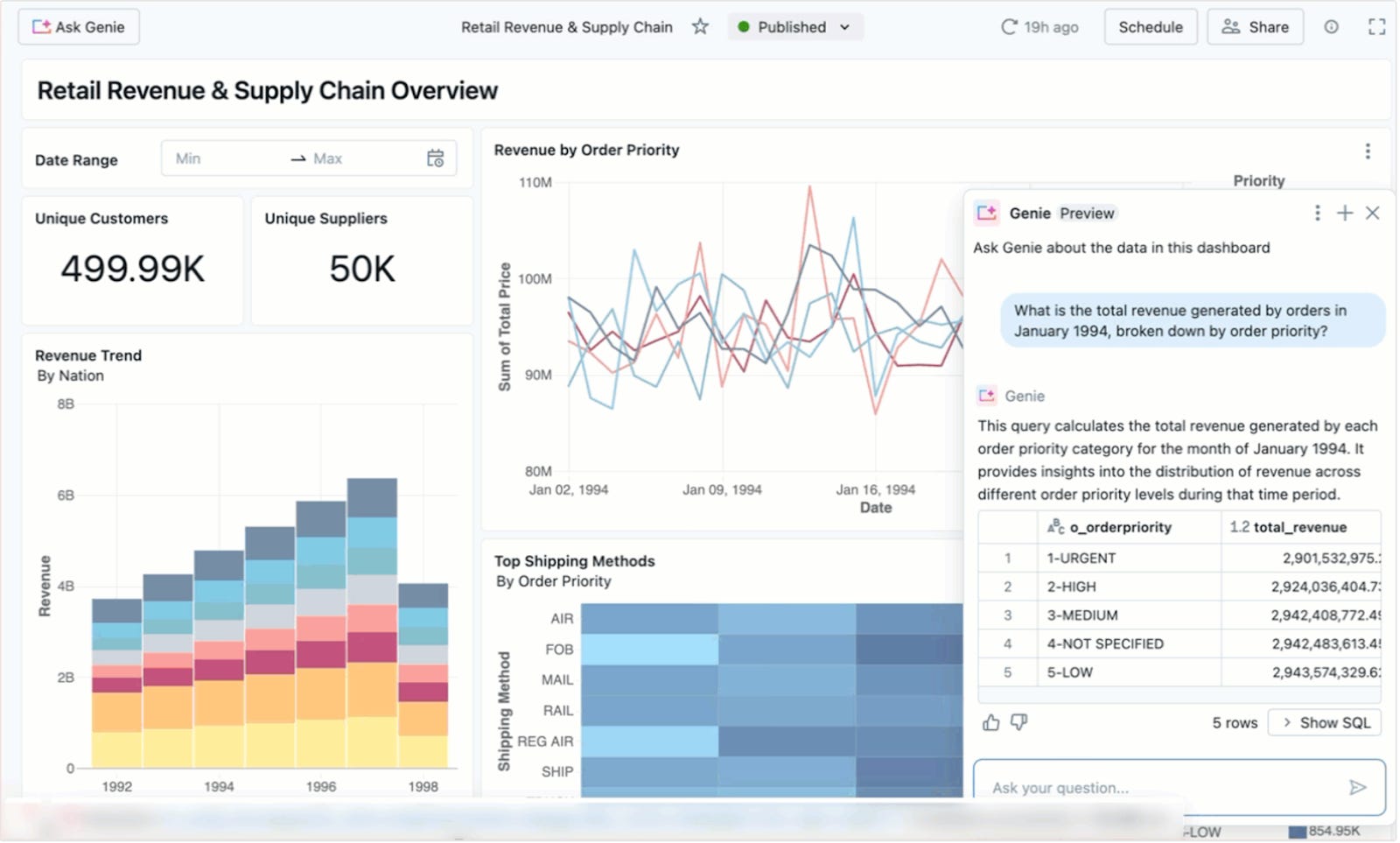
General Updates
Dashboard parameters now support multiple selections & date ranges.
Dashboard dataset editor now supports multi-statement queries
Dashboard viewers can now open datasets in a new table from the canvas of a published dataset, making it much easier to view the data behind the visuals
Embedding
Dashboard embedding is now generally available, so you can now embed an AI/BI dashboard in an external website or application
AI/BI Genie
General Updates
Genie space authors can now add markdown descriptions to provide users with guidance on using their space.
Query results can now be downloaded up to 1GB in a csv file.
Genie is now turned on by default in the workspace toggle
More tables can now be added via the Add Data button in the Data tab
Databricks SQL
Streaming Tables and Materialized Views
Streaming tables now support time travel to allow you to query previous table versions based on timestamp or table versions
Schedules for streaming tables and materialized Views created via Databricks SQL now use human-readable syntax instead of CRON scheduling.
General Updates
In DBR 14.3 and above, running a SQL query in notebook generates an implicit DataFrame (_sqldf) that can be reused downstream, which is an addition to the _sqldf variable in Python cells.
GenAI & ML
Mosaic AI Model Training has been rebranded to Foundation Model Fine-tuning and AutoML. → Documentation
Foundation Model APIs pay-per-token workloads are now supported in all regions where Mosaic AI Model Serving is available. If your workspace is in a Model Serving region but not in a U.S. or EU region, your workspace must be enabled for cross-Geo data processing. → Documentation
Breaking change: Hosted RStudio is end-of-life in Databricks Runtime 16.0 and above. → Documentation
How to: Serving Vision Language Models on Databricks | Mlflow Extensions → Demo
How to: Using GenAI and Traditional ML for Anomaly & Outlier Detection → Demo
How to: Optimise RAG applications with semantic caching on Databricks → Demo