

What's new in Databricks - October 2025

October 2025 Release Highlights
Mosaic AI Model Serving adds support for GPT‑5, Claude Sonnet 4.5, Qwen3 Next, Gemini 2.5 Pro, and multimodal inputs, with autoscaling improvements and prompt caching for Claude models.
Databricks introduces Context‑based ingress control and AI‑powered data classification to enhance security and compliance governance.
AIBI Genie and Dashboards receive major updates including SQL result summaries, benchmark enhancements, top/bottom N chart categories, and waterfall visualizations.
Serverless OCR is now available through ai_parse_document!
Zerobus now available (stream record by record to your UC Tables!)
UC Compatibility Mode now enables external tools like Snowflake, Athena, and Microsoft Fabric to read Unity Catalog managed tables and materialized views efficiently.
Building the future of AI: Classic ML to GenAI with Patrick Wendell Databricks Co-Founder
Want to know more about the AI market, Databricks MosaicAI and how to build AI products like Agent Bricks in a massive organization like Databricks? Listen to Patrick Wendell, Databricks CoFounder share his AI insights!
🛠️Data Engineering
Convert to Unity Catalog managed table for external table
Check out this quick video to discover how to migrate External Table to UC Managed table!
Smaller table, faster queries! Zstd is now the default compression for new Delta Tables
All newly created Delta tables in Databricks Runtime 16.0 and above use Zstandard compression by default instead of Snappy.
Existing tables continue to use their current compression codec. To change the compression codec for an existing table, set the delta.parquet.compression.codec table property
Access UC Managed table with other engine through Compatibility Mode
UC Compatibility Mode generates a read-only version of a Unity Catalog managed table, streaming table, or materialized view that is automatically synced with the original table. This enables external Delta Lake and Iceberg clients, such as Amazon Athena, Snowflake, and Microsoft Fabric to read your tables and views without sacrificing performance on Databricks. Save the data in UC, read it from other engines! 📖 Documentation
OCR made simple with ai_parse_document
The ai_parse_document enables users to extract structured content and contextual layout metadata from unstructured documents, such as PDFs and images (JPEG, PNG), using state-of-the-art generative AI models provided through Mosaic AI Model Serving APIs. 📖 Documentation
Zerobus Ingest connector in Lakeflow Connect is available
One of the most Exciting release! Having kafka queue or similar system to ingest data into your UC tables? Zerobus Ingest provides a fully manage experience through API!

The Zerobus Ingest connector enables record-by-record data ingestion directly into Delta tables through a gRPC API (more APIs to come!). This serverless connector operates at any scale and streamlines ingestion workflows by eliminating the need for message bus infrastructure and Delta-specific dependencies. 📖 Documentation
input_file_name is no longer supported
Prefer the new _metadata.file_name!

Auto Loader incremental listing default changed
cloudFiles.useIncrementalListing option has changed from auto to false
Support MV/ST refresh information in Describe extended as Json

🪄Serverless
Version 17.3
LIMIT ALL support for recursive CTEs: You can now use the
LIMIT ALLclause with recursive common table expressions (rCTEs) to explicitly specify that no row limit should be applied to the query results.📖 DocumentationAppending to files in Unity Catalog volumes returns correct error: Attempting to append to existing files in Unity Catalog volumes now returns a more descriptive error message to help you understand and resolve the issue.
st_dumpfunction support: You can now use thest_dumpfunction to decompose a geometry object into its constituent parts, returning a set of simpler geometries.Polygon interior ring functions are supported:
st_numinteriorrings: Get the number of inner boundaries (rings) of a polygon.st_interiorringn: Extract the n-th inner boundary of a polygon and return it as a linestring.
EXECUTE IMMEDIATE using constant expressions: The
EXECUTE IMMEDIATEstatement now supports using constant expressions in the query string, allowing for more flexible dynamic SQL execution. 📖 DocumentationAllow
spark.sql.files.maxPartitionBytesin serverless compute: You can now configure thespark.sql.files.maxPartitionBytesSpark configuration parameter on serverless compute to control the maximum number of bytes to pack into a single partition when reading files. 📖 Documentation
🖥️Platform
New permissions for Databricks Github App
Granting this permission will let Databricks retrieve and save your primary GitHub account email to your Linked Git credential in Databricks
Git email identity configuration for Git folders
You can specify a Git provider email address, separate from your username, when creating Git credentials for Databricks Git folders. This email is used as the Git author and committer identity for all commits made through Git folders, ensuring proper attribution in your Git provider and better integration with your Git account.
Notebook improvements
The cell execution minimap now appears in the right margin of notebooks. Use the minimap to get a visual overview of your notebook’s run status and quickly navigate between cells. 📖 Documentation
Use Databricks Assistant to help diagnose and fix environment errors, including library installation errors. 📖 Documentation
When reconnecting to serverless notebooks, sessions are automatically restored with the notebook’s Python variables and Spark state. 📖 Documentation
Databricks supports importing and exporting IPYNB notebooks up to 100 MB. Revision snapshot autosaving, manual saving, and cloning are supported for all notebooks up to 100 MB.
When cloning and exporting notebooks, you can now choose whether to include cell outputs or not.
Billable usage track the performance mode
Billing logs record the performance mode of Serverless jobs and pipelines. The workload’s performance mode is logged in the product_features.performance_target column and can include values of PERFORMANCE_OPTIMIZED, STANDARD or NULL
Context based ingress control
Context-based ingress enables account admins to set allow and deny rules that combine who is calling, from where they are calling, and what they can reach in Databricks. Context-based ingress control ensures that only trusted combinations of identity, request type, and network source can reach your workspace. A single policy can govern multiple workspaces, ensuring consistent enforcement across your organization. 📖 Documentation
Lakeflow Jobs Updates
Create backfill job runs to backfill data from the past. This is useful for loading older data, or repairing data when there are failures in processing
Jobs can be triggered on source table update
Unified runs list
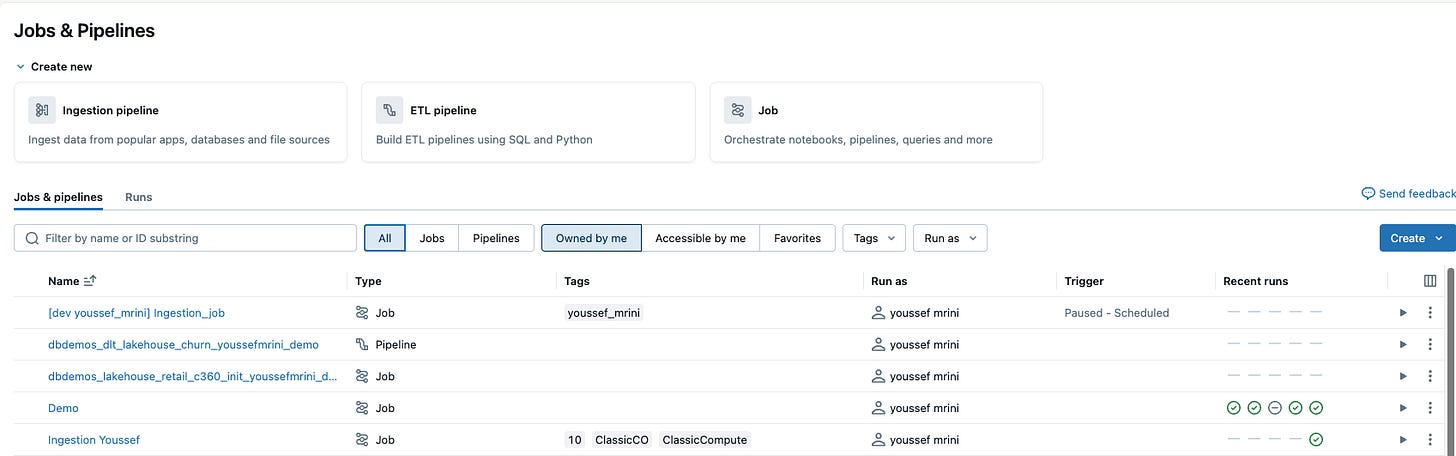
Databricks Connector for Google Sheets offers additional features

Configure compute to AWS Capacity Blocks
You can use Databricks data to build canvas apps in Power Apps, flows in Power Automate and agents in Copilot Studio by creating a Databricks connection in Power Platform. 📖 Documentation
🤖GenAI & ML
Mosaic Models Serving updates
Mosaic AI Model Serving supports Anthropic Claude Sonnet 4 for batch inference workflows
Mosaic AI Model serving support OpenAI GPT 5 Models
Alibaba Cloud Qwen3_Next instruct, Anthropic Claude Sonnet 4.5, Gemini 2.5 Pro and Flash Models are available on Pay-Per-Token
Prompt Caching is supported for Claude Models
Prompt caching is supported for Databricks-hosted Claude models. You can specify the cache_control parameter in your query requests to cache the following:
Thinking messages content in the
messages.contentarray.Images content blocks in the
messages.contentarray.Tool use, results and definitions in the
toolsarray.
Model Serving improvements
Mosaic AI Model Serving supports multimodal inputs for Databricks hosted foundation models. 📖 Documentation
Autoscaling in Mosaic AI Model Serving has been tuned to ignore extremely brief traffic surges and instead respond only to sustained increases in load. This change prevents unnecessary provisioned concurrency scaling during momentary bursts and reduces serving costs without impacting performance or reliability.
Data Classification powered by AI
Databricks offers advanced data classification capabilities powered by AI, making it easy to automatically identify, classify, and tag sensitive data in any table or dataset within Unity Catalog. AI-driven classification streamlines compliance, simplifies governance, and helps teams apply access control policies through features like attribute-based access control (ABAC)

SQL MCP Server is available
Databricks provides a SQL managed MCP server that allows AI agents to execute SQL queries directly against Unity Catalog tables using SQL warehouses. 📖 Documentation
Multi-Agent Supervisor supports Unity Catalog functions and external MCP Servers
Multi-Agent Supervisor to create a supervisor system that coordinates Genie Spaces, agent endpoints and tools to work together to complete complex tasks across different, specialized domains. You can provide the supervisor system tools like Unity Catalog functions and external MCP servers.
📝AIBI Genie
Add tables and metric views to spaces: Users can add tables and metric views to a space and analyze them together.
Benchmarks scoring improvement: Benchmarks treat extra rows or columns in Genie’s output as incorrect. 📖 Documentation
Thinking steps in responses: Each Genie response now includes thinking steps that show how the prompt was interpreted, along with the tables and example SQL statements that were used. 📖 Documentation
Easier benchmark generation:
Space editors can save representative messages or SQL answers from chat conversations to benchmark questions.📖 Documentation
Space editors can generate benchmark SQL answers after entering a benchmark text question. 📖 Documentation
Accurate Genie answers from one benchmark result can now be saved to update future benchmark sets. 📖 Documentation
Improved performance and latency: Genie’s internal reasoning process has been simplified, slightly improving overall latency and streamlining context for SQL generation.
JOIN relationship discovery improvements: You can sort
JOINrelationships and SQL snippet definitions for easier management.API endpoints moving to Public Preview:list conversation messages, delete conversation message, and send thumbs up/down feedback.
Benchmark result explanations: Benchmark results include an explanation for why a result was rated incorrect.
SQL execution result summaries: Genie automatically generates summaries of SQL execution results to make responses more natural and easier to interpret.
SQL measures in knowledge stores: Users can add SQL measures to a space’s knowledge store, along with filters and dimensions, to guide Genie in generating specific SQL expressions. 📖 Documentation
Fixed permissions messaging: Messaging for users with CAN RUN or CAN VIEW permissions has been corrected to accurately reflect their capabilities in the monitoring and data tabs.
Increased benchmark limit: The maximum number of benchmarks you can add to a Genie space has been raised from 100 to 500.
Run benchmarks selectively: You can select a subset of benchmark questions to start a run from either the benchmark list page or from a previous benchmark result. 📖 Documentation
Unity Catalog SQL functions as benchmark answers: You can add Unity Catalog SQL functions as gold standard answers to benchmarks for more comprehensive testing.
📊AIBI Dashboard
Access for account-level users: Users without a workspace can access dashboards shared with them that were published without embedded credentials. 📖 Documentation
Preview fields and measures for metric views: Authors can preview available fields and measures for metric views in the Add data dialog.
Query insights in the dashboard dataset editor: Query insights are available in the dashboard dataset editor to help analyze query performance.
Copy and paste widgets and pages: Dashboard widgets and pages can be copied and pasted between dashboards.
Top or bottom N categories in bar charts: Bar charts can now display the top or bottom N categories. To edit, open the kebab menu for the categorical axis dimension and set the number under Default number of categories.
Adjustable line thickness in line charts: You can control the thickness of lines in line charts. If no series are specified in the size area, the slider changes all line thickness uniformly. If series are specified, you can set different thickness values for each series, similar to different size circles in scatter charts.
Copy link URLs from tables: You can copy link URLs directly from table visualizations.
Additional predicate support for custom calculations: Custom calculations now support
IN,BETWEEN, and pattern matching predicates (LIKE,ILIKE,RLIKE) for more flexible filtering and comparison operations. 📖 DocumentationDynamic text functions in pivot tables: Pivot tables support
contains(),startswith(), andendswith()functions for conditional formatting.Gridline toggle: Charts support toggling gridlines on and off.📖 Documentation
Dashboard tags and certification: You can add tags to dashboards and Genie spaces to improve organization across your workspace.
Drill-through without target filters: Drill-through filters any visualization based on the same dataset as the source selection without an explicit target filter. If a target filter exists, it is still applied. 📖 Documentation
New functions for custom calculations: Custom calculations support over 170 functions. 📖 Documentation
Drag-and-drop field reordering in visualizations: Authors can drag to reorder fields when creating some visualizations such as Pivot and Line charts.
Waterfall visualization type: Waterfall charts are available for dashboards. 📖 Documentation
🛡️Governance
Certification status system tag
Delta Sharing recipients can apply row filters and column masks
Delta Sharing recipients can apply their own row filters and columns masks on shared tables and shared foreign tables.Delta Sharing providers still cannot share data assets that have row-level security or column masks.
🔍 Data Warehousing
You can define semantic metadata in a metric view. Semantic metadata helps AI tools such as Genie spaces and AI/BI dashboards interpret and use your data more effectively.
To use semantic metadata, your metric view must use YAML specification version 1.1 or higher and run on DBR 17.2 or above. 📖 Documentation
That’s it for all the latest news!
Don’t miss any update, don’t forget to subscribe!