

Part2: Implementing a RAG chatbot with Vector Search, BGE, langchain and llama2 on Databricks
Part2: Creating your Vector Search Index with Databricks Foundation model embeddings

Creating a Vector Search Index on your Delta Table
In part 1, we discussed how data should be prepared to extract text and create chunks from your knowledge database (documentation, pdf or docx…).
All the chunks are now saved as a Delta Table within Unity Catalog.
It’s now time to create a Vector Search Index on top of your databricks_documentation table and provide real-time similarity search capabilities on top of the chunks we extracted. We’ll use the result of the similarity search to augment our LLM prompt with additional content.

Creating the Index on top of the table
Let’s add a vector search index to our databricks_documentation table.
A Vector Search Index contains an embedding (vector) representing your text in a fixed space. To make this easy, Databricks provides embeddings Foundation Model (BGE), automatically computing the chunks embeddings for you.
This is a very straightforward step:
First, create a Databricks Vector Search endpoint (in the compute page). You just need to provide a name, and it’ll start your endpoint, ready to accept REST API calls to search similar content, within any index.
Then, select the table within the Unity Catalog menu and create the index: give it a name, select the endpoint, the text column to index (your chunks: “content”) and your BGE embedding model.
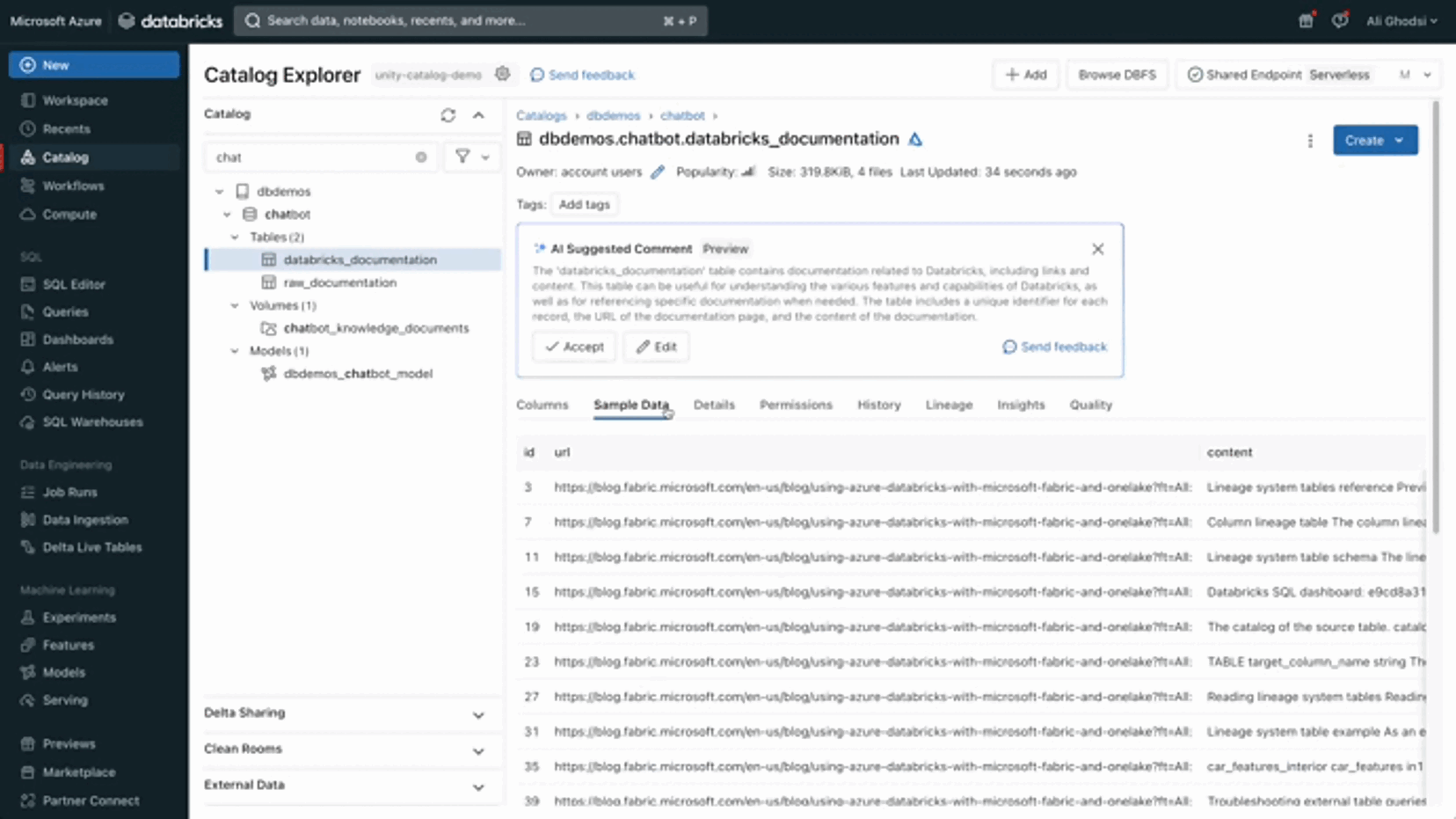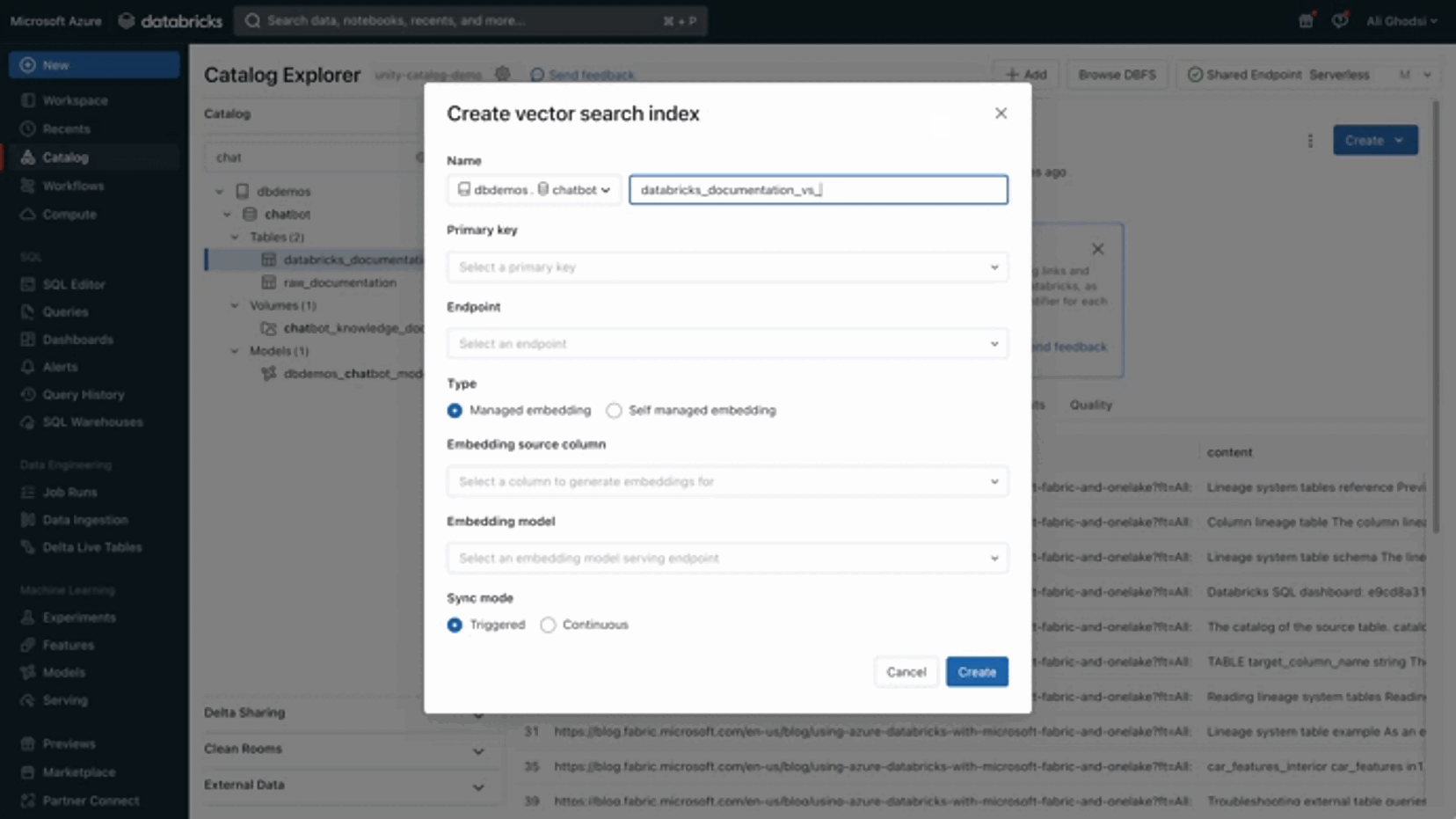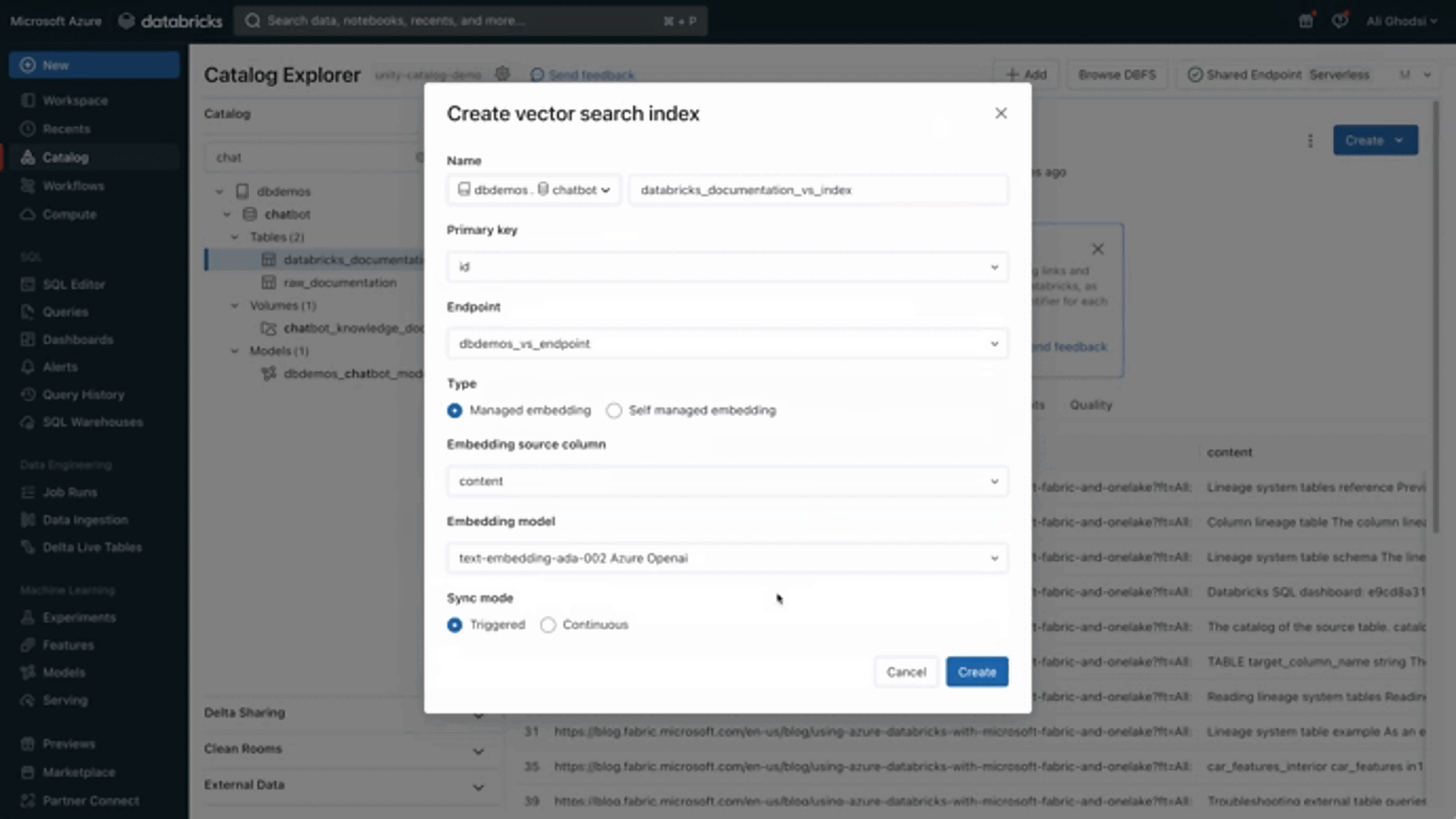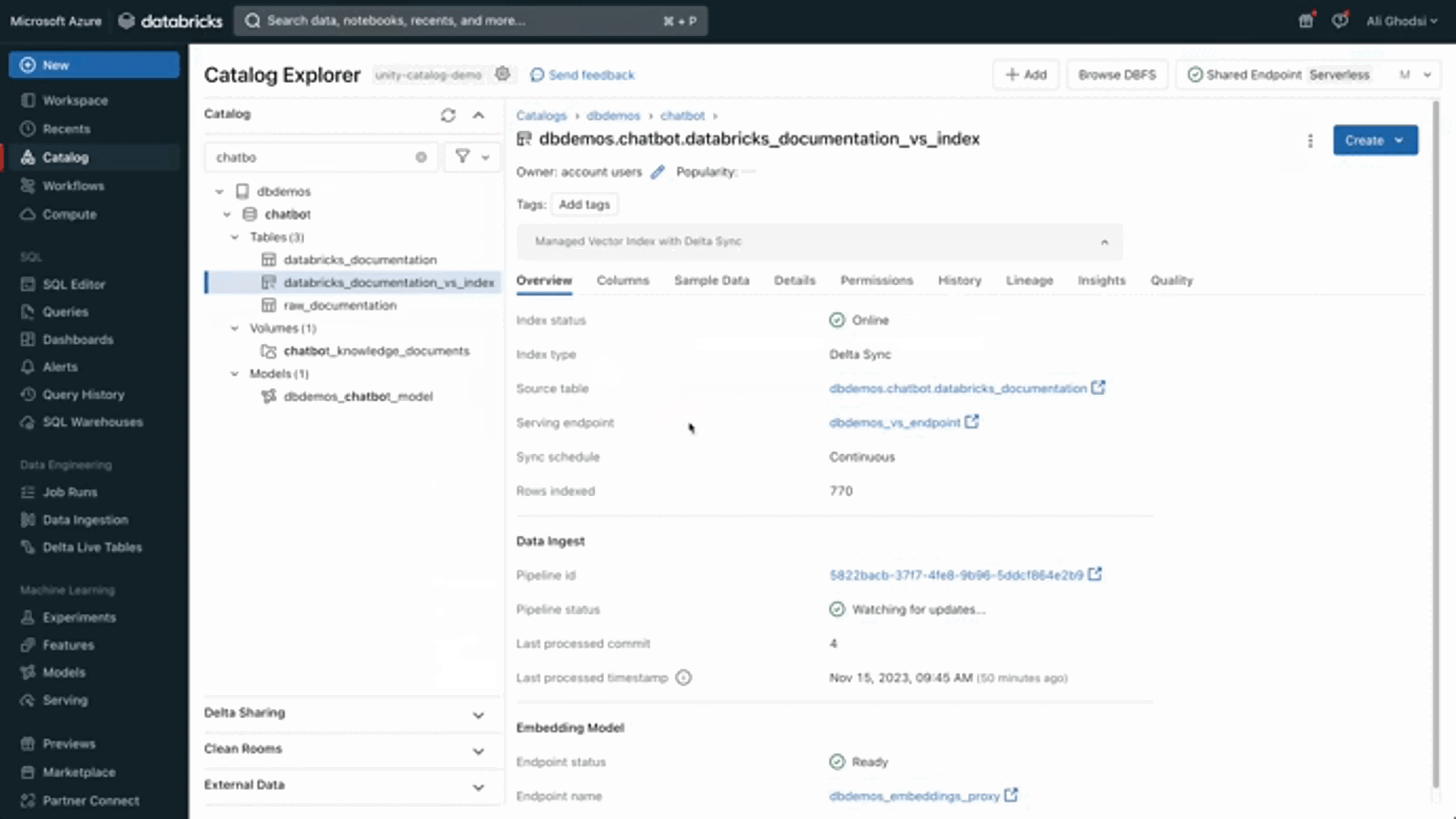
That’s all you have to do. Databricks will keep the index in synch for you: as soon as you add a value to your table, the index will update accordingly (Continuous sync). Note that you can select “Trigger sync” to only refresh the index when you wish (providing the best TCO, similar to a triggered spark streaming application).
A note on index types
Note that Databricks offers 3 types of indexes:
Managed embeddings (what we just discussed, Databricks automatically computes the embeddings during indexation and search)
Self Managed embeddings (you compute the embeddings yourself)
Direct index (when you don’t have a Delta table and index yourself the data)
If you’re not sure and want to add an index on a Delta table, go with the default Managed embeddings.

Searching for similar content
Now that our index is ready and kept up to date by Databricks, we can query it with Databricks python SDK (or through the REST API).
#get the index
index = vsc.get_index("your_endoint_name", "catalog.schema.index")
#Search the top 2 chunks containing content about billing
similar_chunks = index.similarity_search(
query_text="How can I track my billings?",
columns=["url", "content"],
num_results=2
)Chunk size, embeddings & token pricing
Choosing your chunk size and preparing the data is a good place to start thinking about price. Our next steps will leverage LLMs to:
Compute our chunks embeddings (vector representing the chunk in a fixed space)
Call the foundation chat model with the prompt + RAG chunks
Note: we’ll use high-level price overview as an approximation, please check the actual price based on your model/region
Embeddings price
The embedding price is around $0.0001 / 1K tokens (BGE). If we have ~10 000 documentation pages, each of them of ~1000 tokens, computing our embeddings will cost us 10 000x$0.0001 which is around $1.
Not very significant for our use-case as we won’t re-compute embeddings very often (only when the doc changes).
Chat / Completion Foundation model price
Llama 2 70B foundation model range around $0.002 / 1k-tokens. If we feed the prompt with 3 chunks of 500 tokens plus the answer, each call will be around 3k. Let’s round this to 4k as chatbot often have intermediate call, which gives us 4*$0.002=$0.008, or $8 per 1 000 question asked.
Model like GPT-4 is more expensive, around $0.03 / 1K tokens, or $120 per 1000 question asked in your RAG application.
Want to try this yourself? Get started quickly with an advanced RAG demo on Databricks
What’s next: deploying your langchain model
We have now ingested our documents within a data pipeline, and created a Vector Search Index to find relevant documents to answer a given question.
We’re ready to deploy our model which will be in charge of crafting the prompt, enriched with the documentation, and sending it to an external model (such as llama2, openAI or mistral)
Don’t miss the model deployment: subscribe to our newsletter